Publications
Selected publications in reverse chronological order.
For the full list, see Jaejun Yoo's Google Scholar.
2025
- ICCV
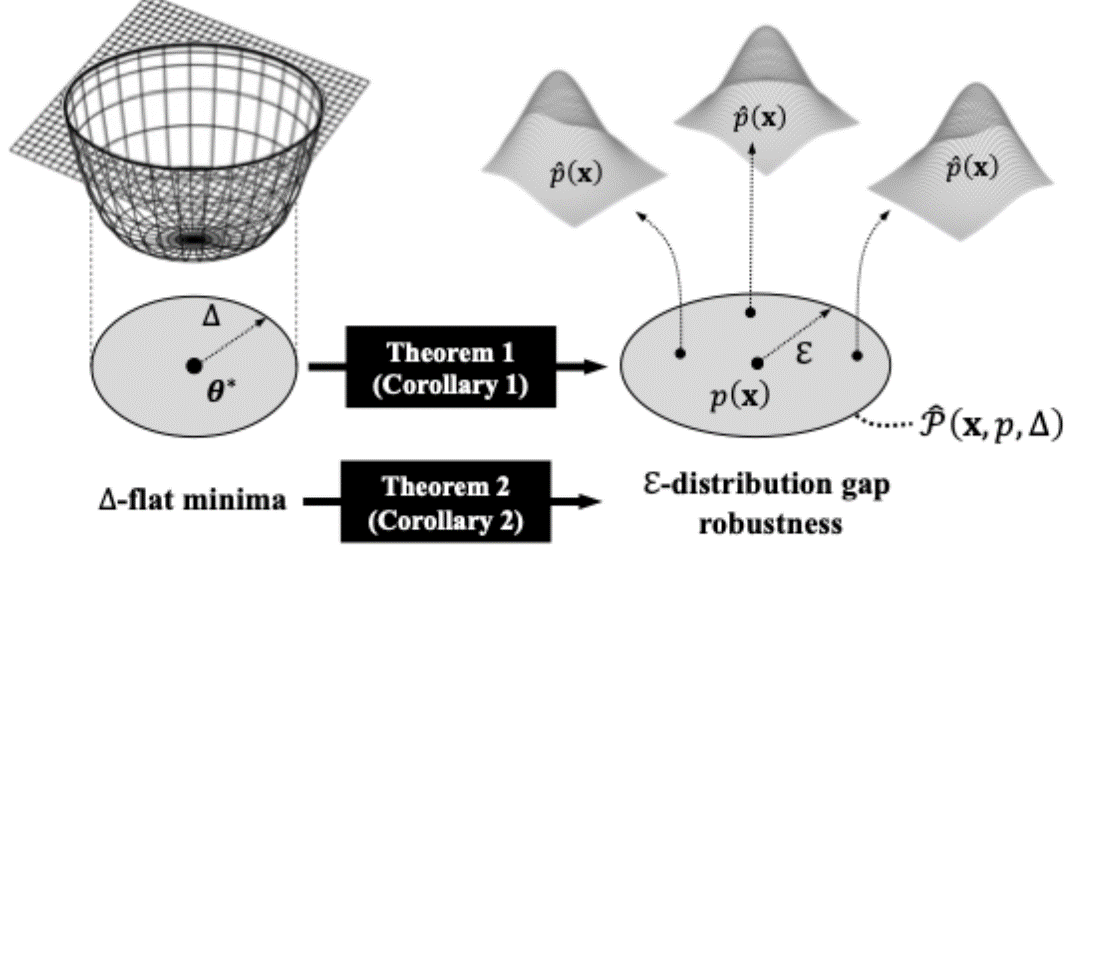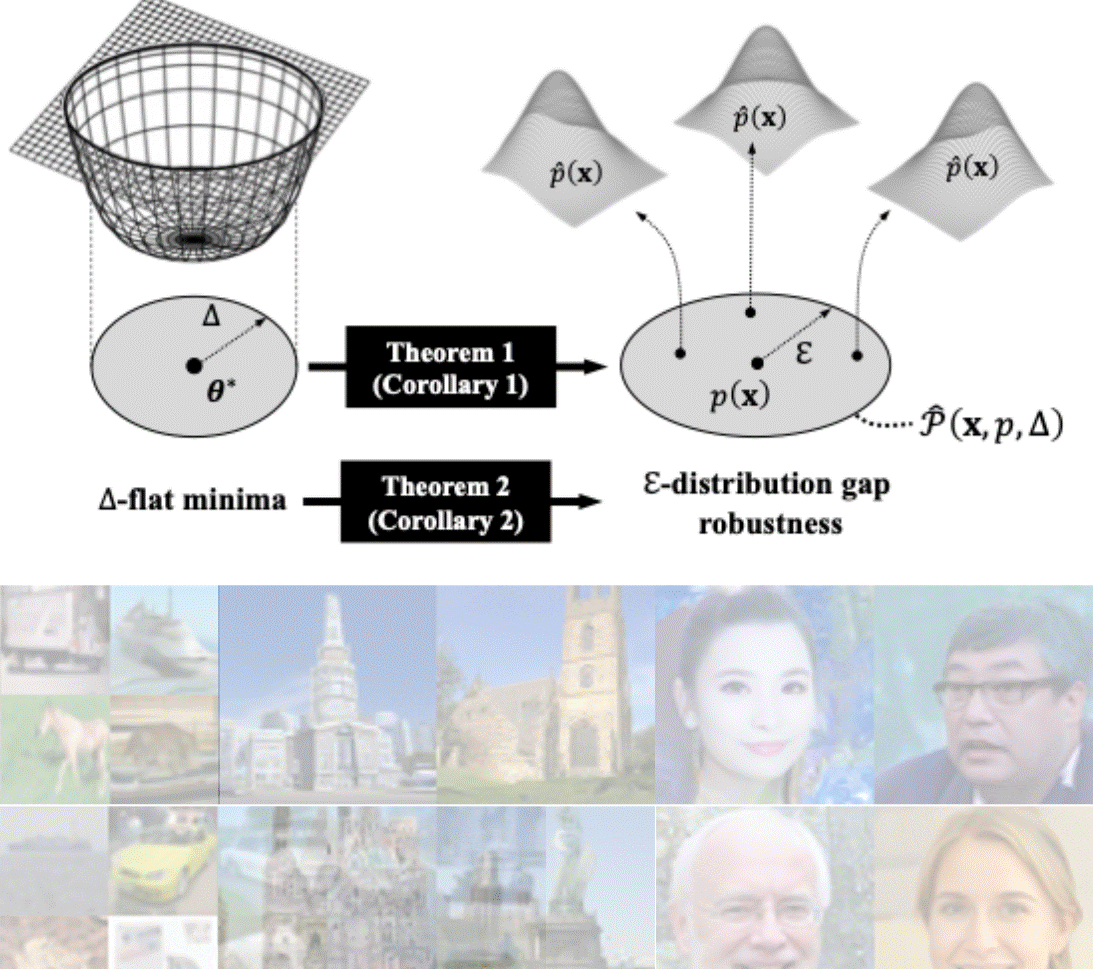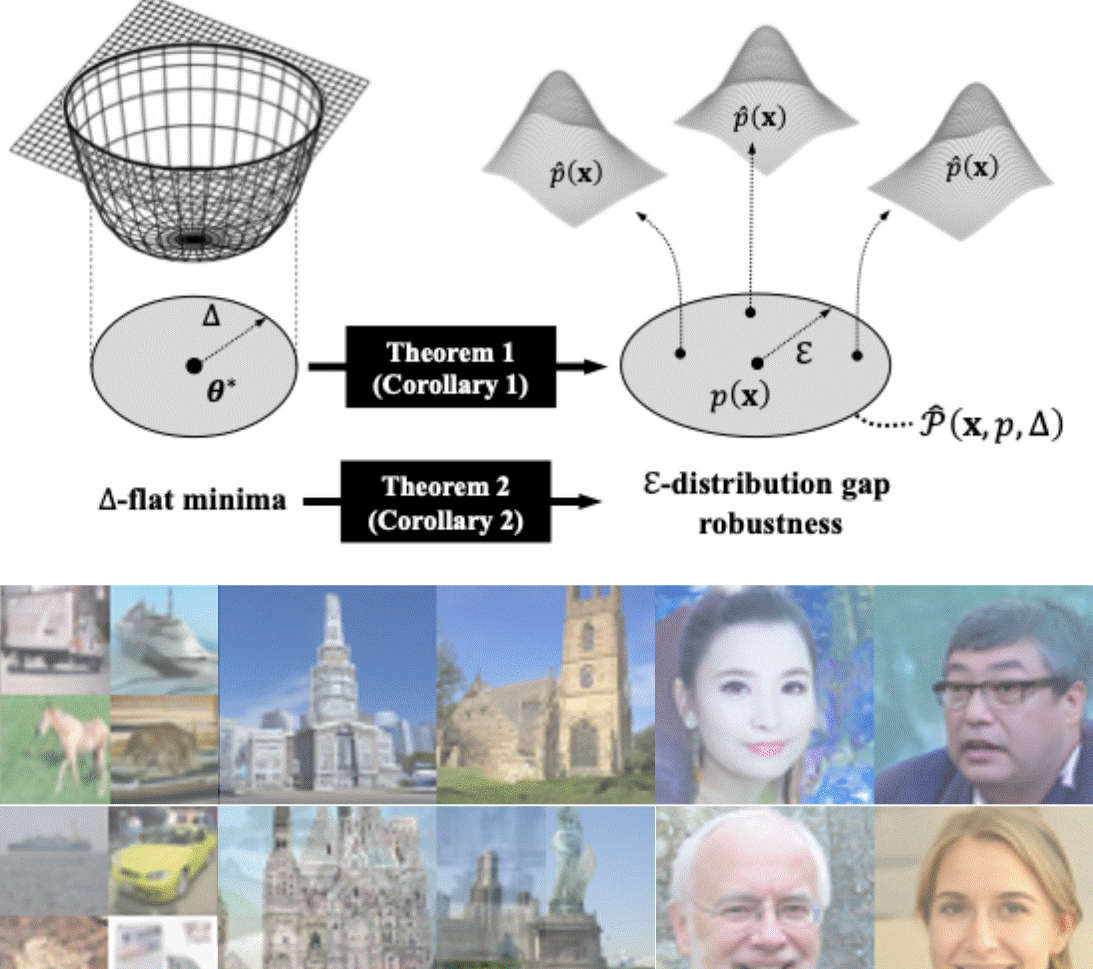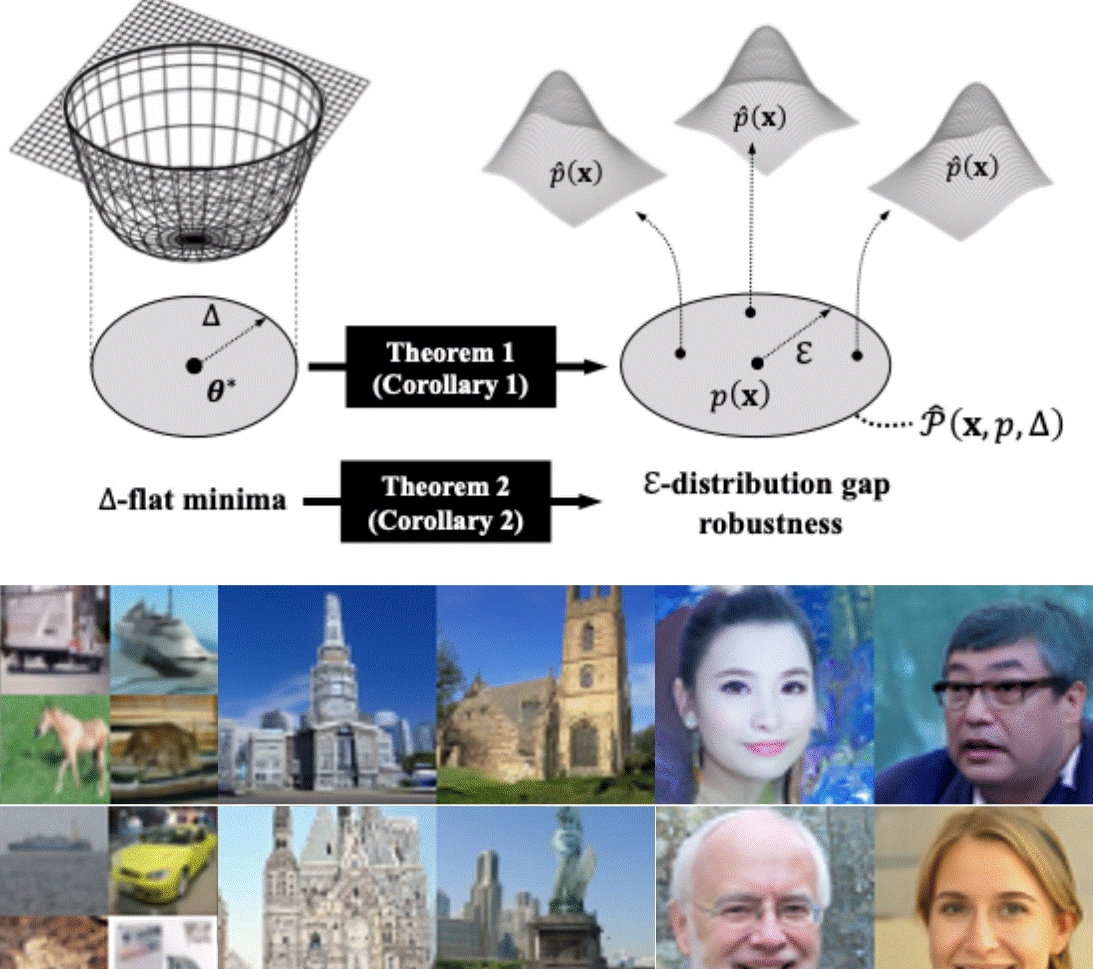
 Understanding Flatness in Generative Models: Its Role and BenefitsTaehwan Lee*, Kyeongkook Seo*, Jaejun Yoo, and 1 more authorIn International Conference on Computer Vision (ICCV), 2025
Understanding Flatness in Generative Models: Its Role and BenefitsTaehwan Lee*, Kyeongkook Seo*, Jaejun Yoo, and 1 more authorIn International Conference on Computer Vision (ICCV), 2025Flat minima, known to enhance generalization and robustness in supervised learning, remain largely unexplored in generative models. In this work, we systematically investigate the role of loss surface flatness in generative models, both theoretically and empirically, with a particular focus on diffusion models. We establish a theoretical claim that flatter minima improve robustness against perturbations in target prior distributions, leading to benefits such as reduced exposure bias-where errors in noise estimation accumulate over iterations-and significantly improved resilience to model quantization, preserving generative performance even under strong quantization constraints. We further observe that Sharpness-Aware Minimization (SAM), which explicitly controls the degree of flatness, effectively enhances flatness in diffusion models even surpassing the indirectly promoting flatness methods-Input Perturbation (IP) which enforces the Lipschitz condition, ensemblingbased approach like Stochastic Weight Averaging (SWA) and Exponential Moving Average (EMA)-are less effective. Through extensive experiments on CIFAR-10, LSUN Tower, and FFHQ, we demonstrate that flat minima in diffusion models indeed improve not only generative performance but also robustness.
@inproceedings{lee2025flatness, title = {Understanding Flatness in Generative Models: Its Role and Benefits}, author = {Lee, Taehwan and Seo, Kyeongkook and Yoo, Jaejun and Yoon, Sung Whan}, booktitle = {International Conference on Computer Vision (ICCV)}, year = {2025}, } - MICCAI
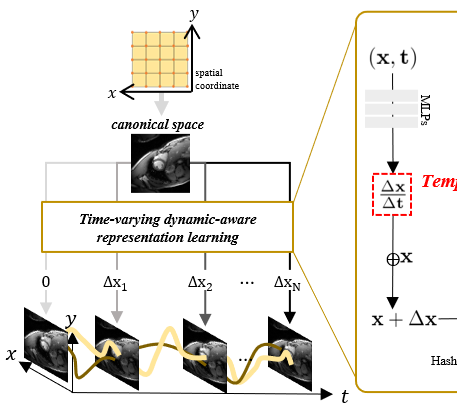
 Dynamic-Aware Spatio-temporal Representation Learning for Dynamic MRI ReconstructionDayoung Baik and Jaejun YooIn Medical Image Computing and Computer Assisted Intervention (MICCAI), 2025
Dynamic-Aware Spatio-temporal Representation Learning for Dynamic MRI ReconstructionDayoung Baik and Jaejun YooIn Medical Image Computing and Computer Assisted Intervention (MICCAI), 2025Dynamic MRI reconstruction, one of inverse problems, has seen a surge by the use of deep learning techniques. Especially, the practical difficulty of obtaining ground truth data has led to the emergence of unsupervised learning approaches. A recent promising method among them is implicit neural representation (INR), which defines the data as a continuous function that maps coordinate values to the corresponding signal values. This allows for filling in missing information only with incomplete measurements and solving the inverse problem effectively. Nevertheless, previous works incorporating this method have faced drawbacks such as long optimization time and the need for extensive hyperparameter tuning. To address these issues, we propose Dynamic-Aware INR (DA-INR), an INR-based model for dynamic MRI reconstruction that captures the spatial and temporal continuity of dynamic MRI data in the image domain and explicitly incorporates the temporal redundancy of the data into the model structure. As a result, DA-INR outperforms other models in reconstruction quality even at extreme undersampling ratios while significantly reducing optimization time and requiring minimal hyperparameter tuning.
@inproceedings{baik2025dainr, title = {Dynamic-Aware Spatio-temporal Representation Learning for Dynamic MRI Reconstruction}, author = {Baik, Dayoung and Yoo, Jaejun}, booktitle = {Medical Image Computing and Computer Assisted Intervention (MICCAI)}, year = {2025}, } - IJCAI
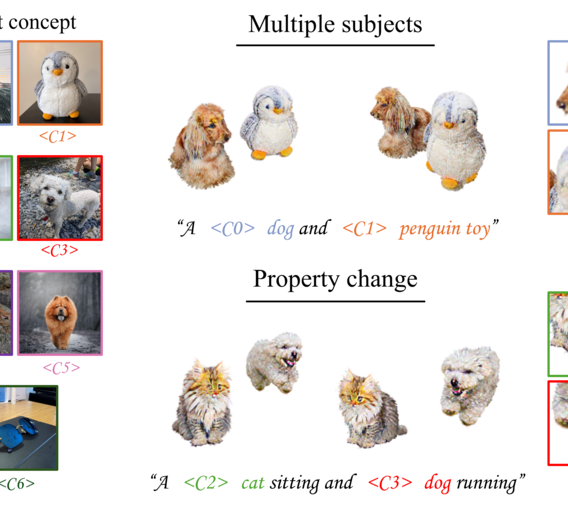
 MultiDreamer3D: Multi-concept 3D Customization with Concept-Aware Diffusion GuidanceWooseok Song, Seunggyu Chang, and Jaejun YooIn International Joint Conference on Artificial Intelligence (IJCAI), 2025
MultiDreamer3D: Multi-concept 3D Customization with Concept-Aware Diffusion GuidanceWooseok Song, Seunggyu Chang, and Jaejun YooIn International Joint Conference on Artificial Intelligence (IJCAI), 2025While single-concept customization has been studied in 3D, multi-concept customization remains largely unexplored. To address this, we propose MultiDreamer3D that can generate coherent multi-concept 3D content in a divide-and-conquer manner. First, we generate 3D bounding boxes using an LLM-based layout controller. Next, a selective point cloud generator creates coarse point clouds for each concept. These point clouds are placed in the 3D bounding boxes and initialized into 3D Gaussian Splatting with concept labels, enabling precise identification of concept attributions in 2D projections. Finally, we refine 3D Gaussians via concept-aware interval score matching, guided by concept-aware diffusion. Our experimental results show that MultiDreamer3D not only ensures object presence and preserves the distinct identities of each concept but also successfully handles complex cases such as property change or interaction. To the best of our knowledge, we are the first to address the multi-concept customization in 3D.
@inproceedings{song2025multidreamer3d, title = {MultiDreamer3D: Multi-concept 3D Customization with Concept-Aware Diffusion Guidance}, author = {Song, Wooseok and Chang, Seunggyu and Yoo, Jaejun}, booktitle = {International Joint Conference on Artificial Intelligence (IJCAI)}, year = {2025}, } - CVPR
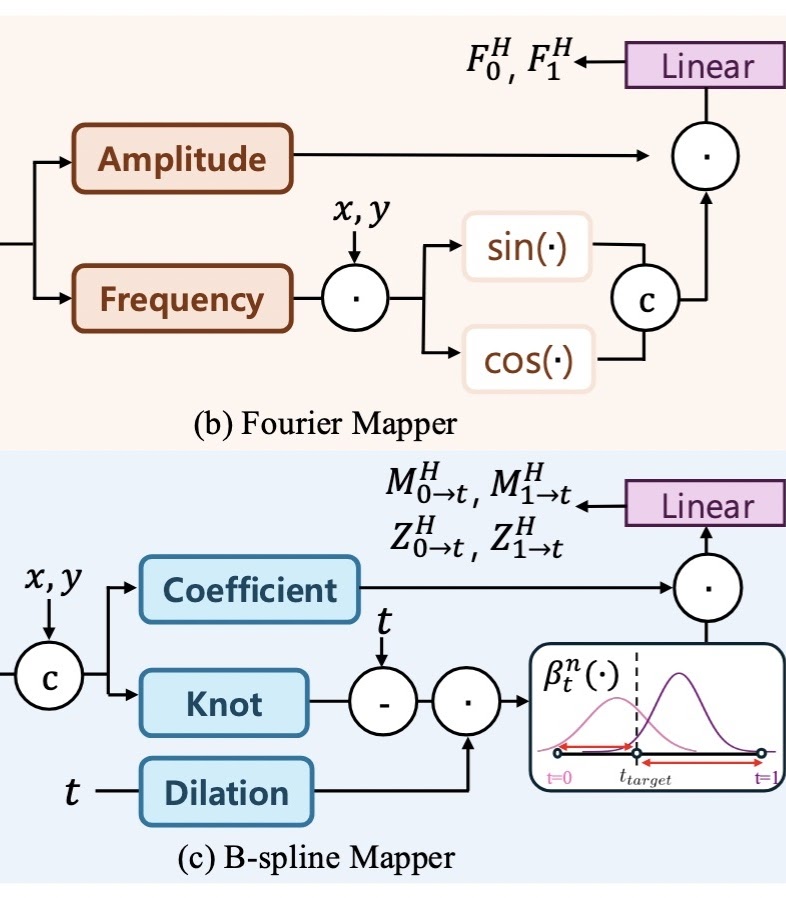
 BF-STVSR: B-Splines and Fourier-Best Friends for High Fidelity Spatial-Temporal Video Super-ResolutionEunjin Kim*, Hyeonjin Kim*, Kyong Hwan Jin, and 1 more authorIn IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2025
BF-STVSR: B-Splines and Fourier-Best Friends for High Fidelity Spatial-Temporal Video Super-ResolutionEunjin Kim*, Hyeonjin Kim*, Kyong Hwan Jin, and 1 more authorIn IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2025While prior methods in Continuous Spatial-Temporal Video Super-Resolution (C-STVSR) employ Implicit Neural Representation (INR) for continuous encoding, they often struggle to capture the complexity of video data, relying on simple coordinate concatenation and pre-trained optical flow networks for motion representation. Interestingly, we find that adding position encoding, contrary to common observations, does not improve—and even degrades—performance. This issue becomes particularly pronounced when combined with pre-trained optical flow networks, which can limit the model’s flexibility. To address these issues, we propose BF-STVSR, a C-STVSR framework with two key modules tailored to better represent spatial and temporal characteristics of video: 1) B-spline Mapper for smooth temporal interpolation, and 2) Fourier Mapper for capturing dominant spatial frequencies. Our approach achieves state-of-the-art in various metrics, including PSNR and SSIM, showing enhanced spatial details and natural temporal consistency. Our code is available {\\color{Cyan}\\text{here}}.
@inproceedings{kim2025bfstvsr, title = {BF-STVSR: B-Splines and Fourier-Best Friends for High Fidelity Spatial-Temporal Video Super-Resolution}, author = {Kim, Eunjin and Kim, Hyeonjin and Jin, Kyong Hwan and Yoo, Jaejun}, booktitle = {IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)}, year = {2025}, } - ICLR
 PRISM: PRivacy-preserving Improved Stochastic Masking for Federated Generative ModelsKyeongkook Seo, Dong-jun Han, and Jaejun YooIn International Conference on Learning Representations (ICLR), 2025
PRISM: PRivacy-preserving Improved Stochastic Masking for Federated Generative ModelsKyeongkook Seo, Dong-jun Han, and Jaejun YooIn International Conference on Learning Representations (ICLR), 2025Despite recent advancements in federated learning (FL), the integration of generative models into FL has been limited due to challenges such as high communication costs and unstable training in heterogeneous data environments. To address these issues, we propose PRISM, a FL framework tailored for generative models that ensures (i) stable performance in heterogeneous data distributions and (ii) resource efficiency in terms of communication cost and final model size. The key of our method is to search for an optimal stochastic binary mask for a random network rather than updating the model weights, identifying a sparse subnetwork with high generative performance; i.e., a “strong lottery ticket”. By communicating binary masks in a stochastic manner, PRISM minimizes communication overhead. This approach, combined with the utilization of maximum mean discrepancy (MMD) loss and a mask-aware dynamic moving average aggregation method (MADA) on the server side, facilitates stable and strong generative capabilities by mitigating local divergence in FL scenarios. Moreover, thanks to its sparsifying characteristic, PRISM yields a lightweight model without extra pruning or quantization, making it ideal for environments such as edge devices. Experiments on MNIST, FMNIST, CelebA, and CIFAR10 demonstrate that PRISM outperforms existing methods, while maintaining privacy with minimal communication costs. PRISM is the first to successfully generate images under challenging non-IID and privacy-preserving FL environments on complex datasets, where previous methods have struggled.
@inproceedings{seo2025prism, title = {PRISM: PRivacy-preserving Improved Stochastic Masking for Federated Generative Models}, author = {Seo, Kyeongkook and Han, Dong-jun and Yoo, Jaejun}, booktitle = {International Conference on Learning Representations (ICLR)}, year = {2025}, } - AAAI
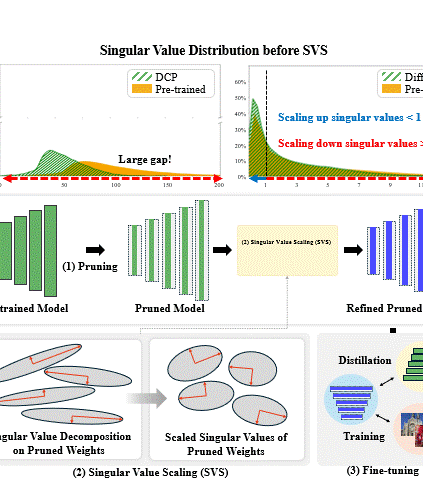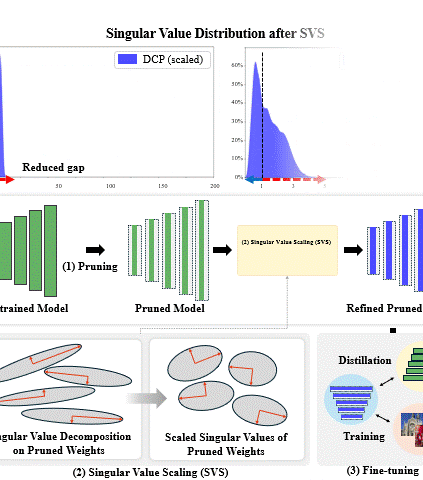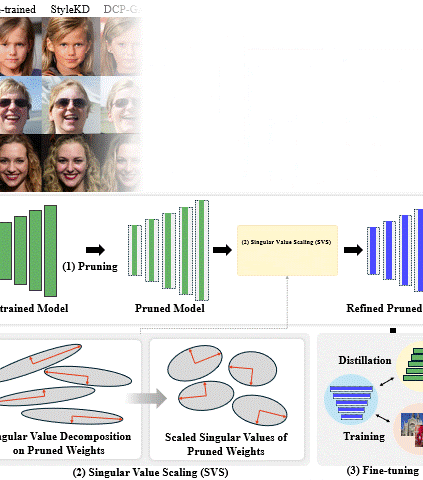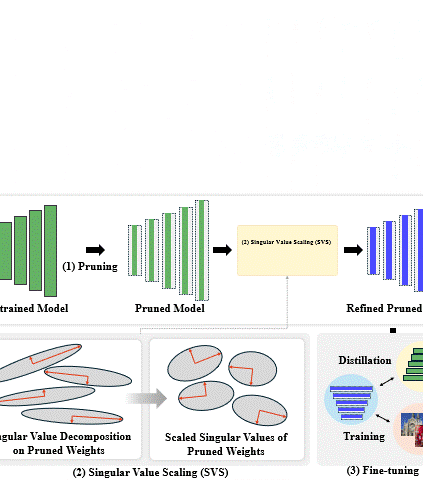
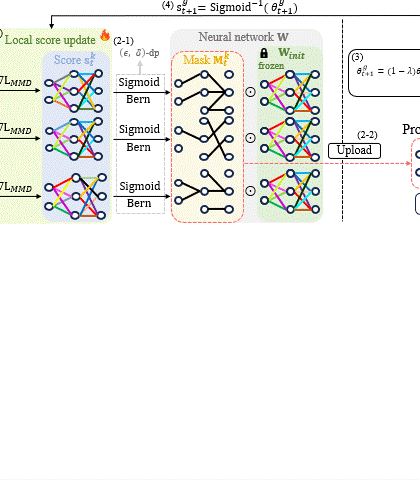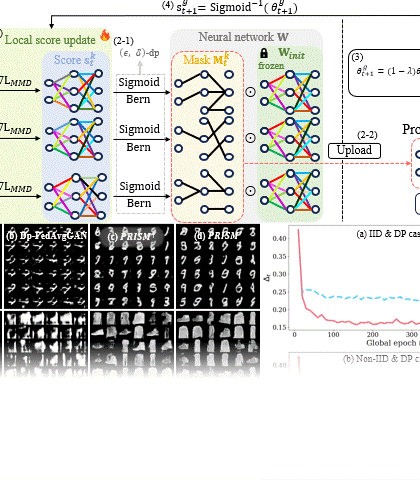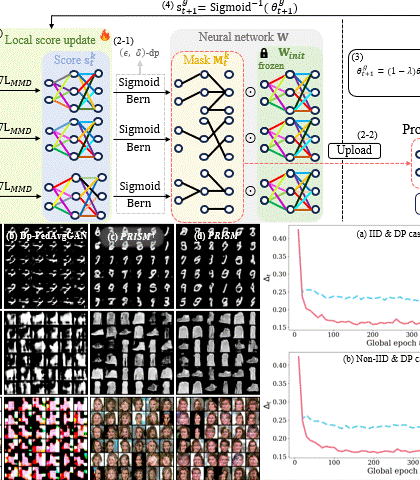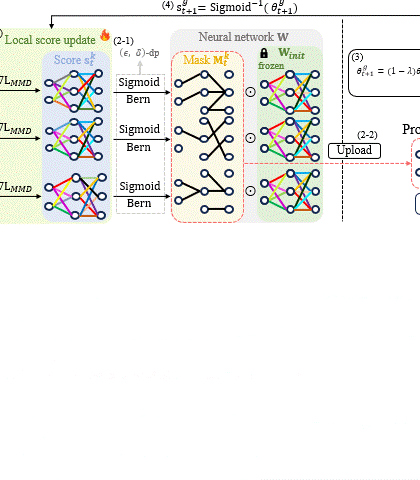 Singular Value Scaling: Efficient Generative Model Compression via Pruned Weights RefinementHyeonjin Kim and Jaejun YooIn AAAI Conference on Artificial Intelligence (AAAI), 2025
Singular Value Scaling: Efficient Generative Model Compression via Pruned Weights RefinementHyeonjin Kim and Jaejun YooIn AAAI Conference on Artificial Intelligence (AAAI), 2025While pruning methods effectively maintain model performance without extra training costs, they often focus solely on preserving crucial connections, overlooking the impact of pruned weights on subsequent fine-tuning or distillation, leading to inefficiencies. Moreover, most compression techniques for generative models have been developed primarily for GANs, tailored to specific architectures like StyleGAN, and research into compressing Diffusion models has just begun. Even more, these methods are often applicable only to GANs or Diffusion models, highlighting the need for approaches that work across both model types. In this paper, we introduce Singular Value Scaling (SVS), a versatile technique for refining pruned weights, applicable to both model types. Our analysis reveals that pruned weights often exhibit dominant singular vectors, hindering fine-tuning efficiency and leading to suboptimal performance compared to random initialization. Our method enhances weight initialization by minimizing the disparities between singular values of pruned weights, thereby improving the fine-tuning process. This approach not only guides the compressed model toward superior solutions but also significantly speeds up fine-tuning. Extensive experiments on StyleGAN2, StyleGAN3 and DDPM demonstrate that SVS improves compression performance across model types without additional training costs.
@inproceedings{kim2025svs, title = {Singular Value Scaling: Efficient Generative Model Compression via Pruned Weights Refinement}, author = {Kim, Hyeonjin and Yoo, Jaejun}, booktitle = {AAAI Conference on Artificial Intelligence (AAAI)}, year = {2025}, }
2024
- ECCV
 HVDM: Hybrid Video Diffusion Models with 2D Triplane and 3D Wavelet RepresentationKihong Kim, Haneol Lee, Jihye Park, and 4 more authorsIn European Conference on Computer Vision (ECCV), 2024
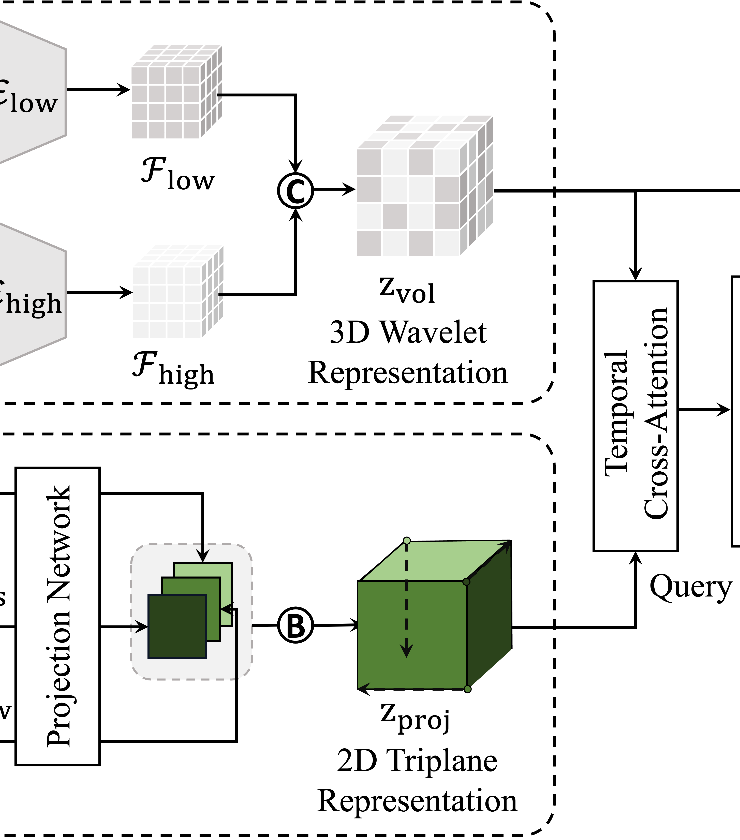
HVDM: Hybrid Video Diffusion Models with 2D Triplane and 3D Wavelet RepresentationKihong Kim, Haneol Lee, Jihye Park, and 4 more authorsIn European Conference on Computer Vision (ECCV), 2024Generating high-quality videos that synthesize desired realistic content is a challenging task due to their intricate high-dimensionality and complexity of videos. Several recent diffusion-based methods have shown comparable performance by compressing videos to a lower-dimensional latent space, using traditional video autoencoder architecture. However, such method that employ standard frame-wise 2D and 3D convolution fail to fully exploit the spatio-temporal nature of videos. To address this issue, we propose a novel hybrid video diffusion model, called HVDM, which can capture spatio-temporal dependencies more effectively. The HVDM is trained by a hybrid video autoencoder which extracts a disentangled representation of the video including: (i) a global context information captured by a 2D projected latent (ii) a local volume information captured by 3D convolutions with wavelet decomposition (iii) a frequency information for improving the video reconstruction. Based on this disentangled representation, our hybrid autoencoder provide a more comprehensive video latent enriching the generated videos with fine structures and details. Experiments on video generation benchamarks (UCF101, SkyTimelapse, and TaiChi) demonstrate that the proposed approach achieves state-of-the-art video generation quality, showing a wide range of video applications (e.g., long video generation, image-to-video, and video dynamics control).
@inproceedings{kim2024hvdm, title = {HVDM: Hybrid Video Diffusion Models with 2D Triplane and 3D Wavelet Representation}, author = {Kim, Kihong and Lee, Haneol and Park, Jihye and Kim, Seyeon and Lee, Kwanghee and Kim, Seungryong and Yoo, Jaejun}, booktitle = {European Conference on Computer Vision (ECCV)}, year = {2024}, } - ECCV
 PosterLlama: Bridging Design Ability of Language Model to Content-Aware Layout GenerationJaejung Seol, Seojun Kim, and Jaejun YooIn European Conference on Computer Vision (ECCV), 2024
PosterLlama: Bridging Design Ability of Language Model to Content-Aware Layout GenerationJaejung Seol, Seojun Kim, and Jaejun YooIn European Conference on Computer Vision (ECCV), 2024Visual layout plays a critical role in graphic design fields such as advertising, posters, and web UI design. The recent trend towards content-aware layout generation through generative models has shown promise, yet it often overlooks the semantic intricacies of layout design by treating it as a simple numerical optimization. To bridge this gap, we introduce PosterLlama, a network designed for generating visually and textually coherent layouts by reformatting layout elements into HTML code and leveraging the rich design knowledge embedded within language models. Furthermore, we enhance the robustness of our model with a unique depth-based poster augmentation strategy. This ensures our generated layouts remain semantically rich but also visually appealing, even with limited data. Our extensive evaluations across several benchmarks demonstrate that PosterLlama outperforms existing methods in producing authentic and content-aware layouts. It supports an unparalleled range of conditions, including but not limited to unconditional layout generation, element conditional layout generation, layout completion, among others, serving as a highly versatile user manipulation tool.
@inproceedings{seol2024posterllama, title = {PosterLlama: Bridging Design Ability of Language Model to Content-Aware Layout Generation}, author = {Seol, Jaejung and Kim, Seojun and Yoo, Jaejun}, booktitle = {European Conference on Computer Vision (ECCV)}, year = {2024}, } - ECCV
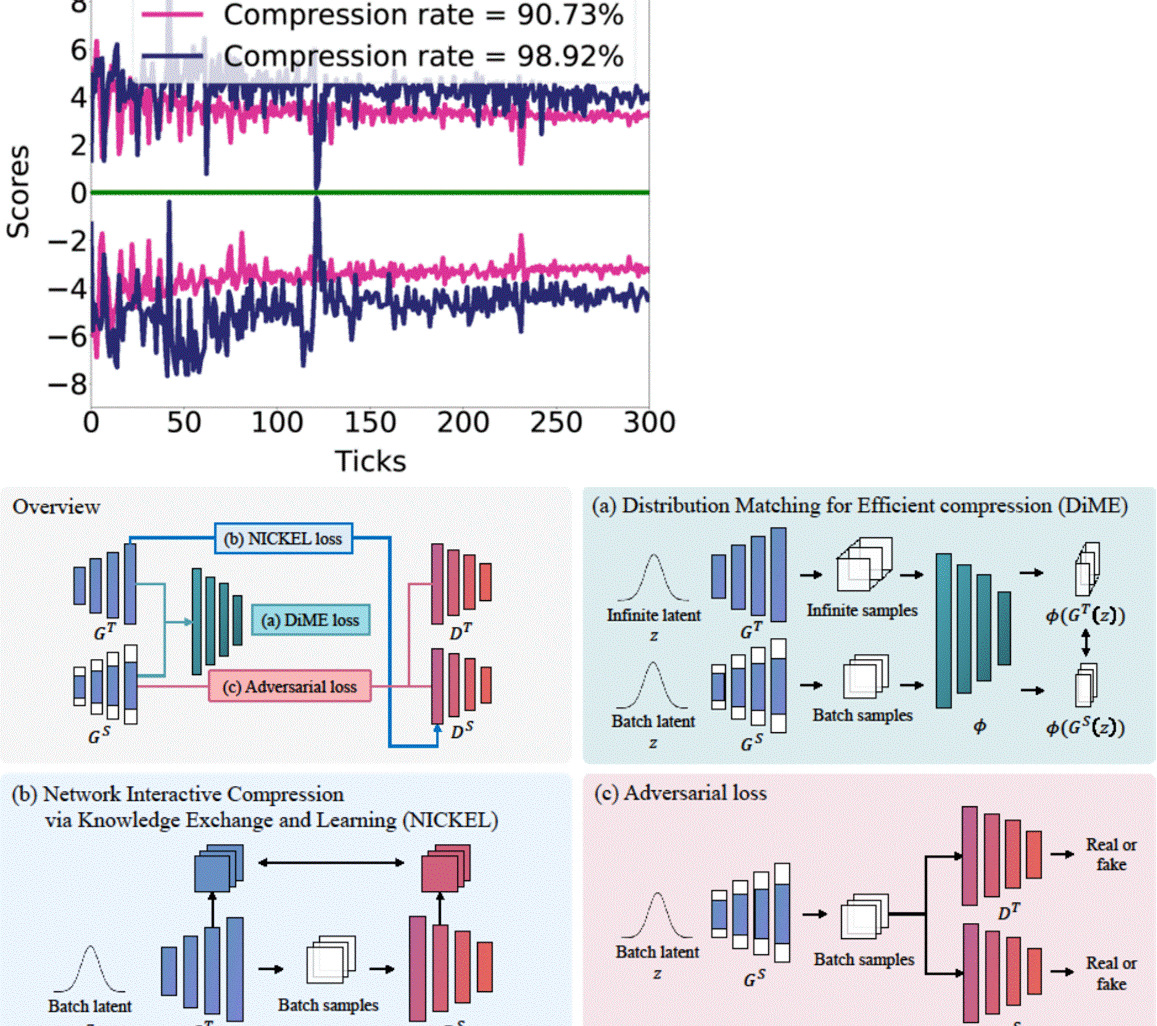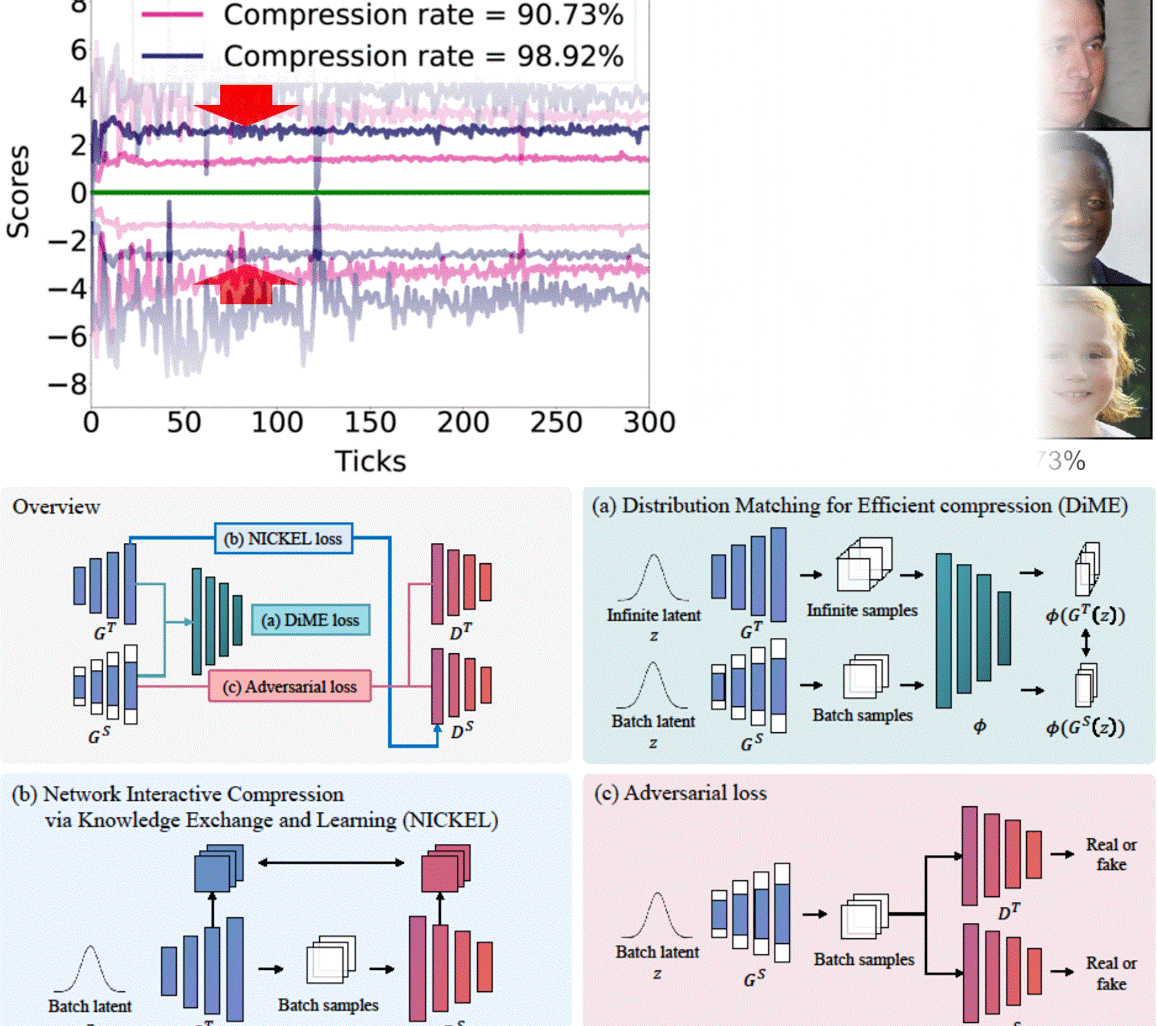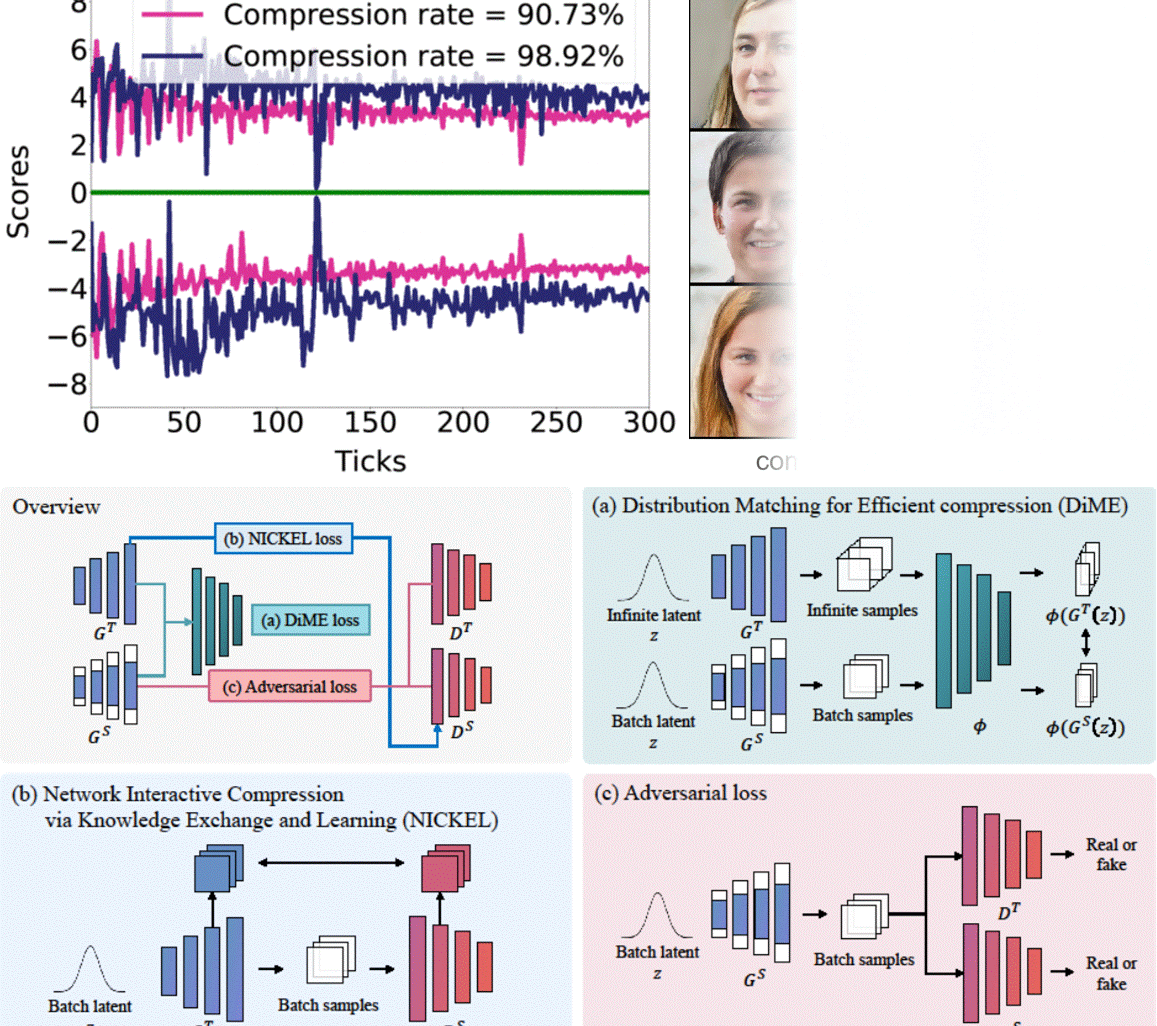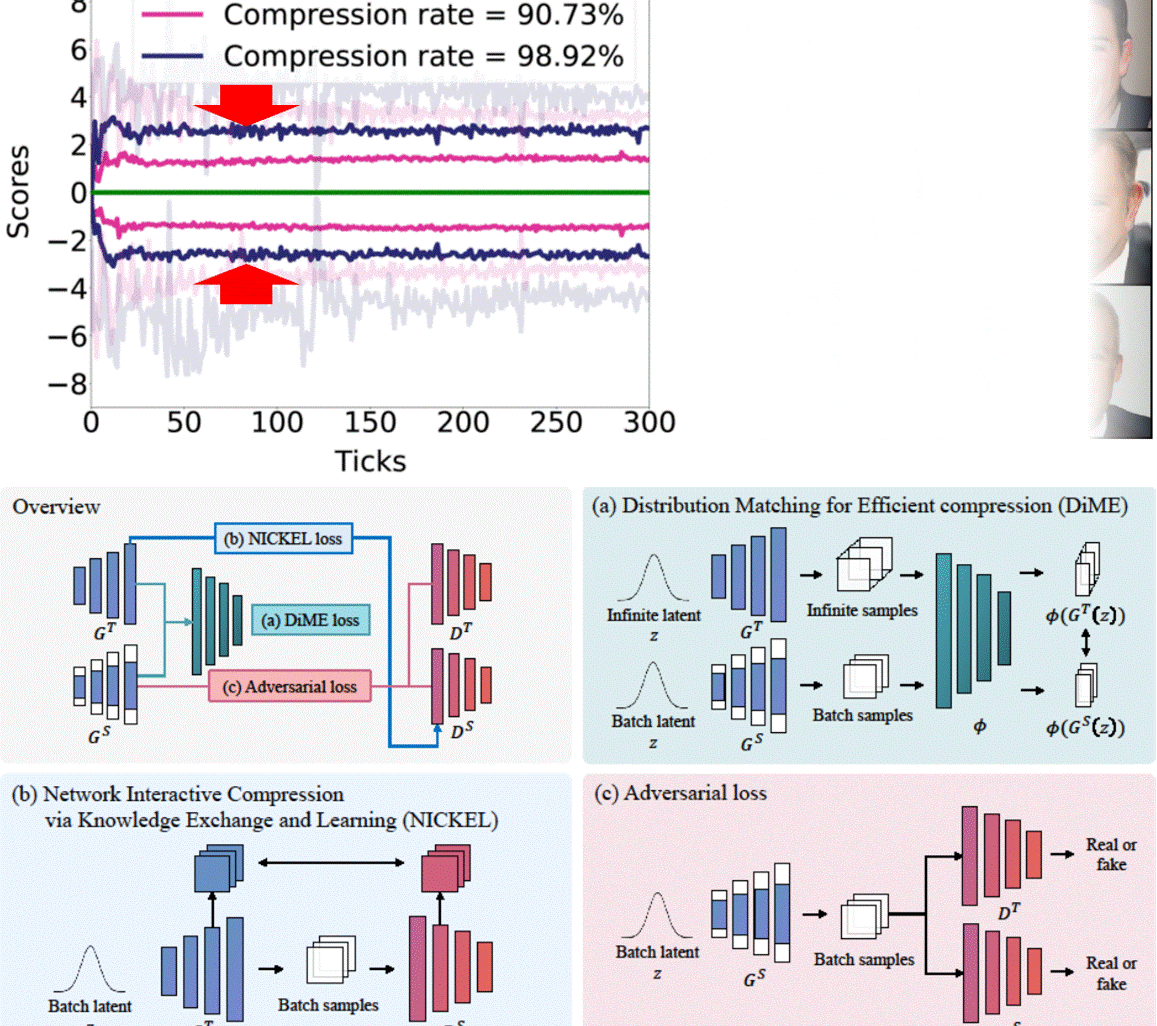
 Nickel and Diming Your GAN: A Dual-Method Approach to Enhancing GAN Efficiency via Knowledge DistillationSangyeop Yeo, Yoojin Jang, and Jaejun YooIn European Conference on Computer Vision (ECCV), 2024
Nickel and Diming Your GAN: A Dual-Method Approach to Enhancing GAN Efficiency via Knowledge DistillationSangyeop Yeo, Yoojin Jang, and Jaejun YooIn European Conference on Computer Vision (ECCV), 2024In this paper, we address the challenge of compressing generative adversarial networks (GANs) for deployment in resource-constrained environments by proposing two novel methodologies: Distribution Matching for Efficient compression (DiME) and Network Interactive Compression via Knowledge Exchange and Learning (NICKEL). DiME employs foundation models as embedding kernels for efficient distribution matching, leveraging maximum mean discrepancy to facilitate effective knowledge distillation. Simultaneously, NICKEL employs an interactive compression method that enhances the communication between the student generator and discriminator, achieving a balanced and stable compression process. Our comprehensive evaluation on the StyleGAN2 architecture with the FFHQ dataset shows the effectiveness of our approach, with NICKEL&DiME achieving FID scores of 10.45 and 15.93 at compression rates of 95.73% and 98.92%, respectively. Remarkably, our methods sustain generative quality even at an extreme compression rate of 99.69%, surpassing the previous state-of-the-art performance by a large margin. These findings not only demonstrate our methodologies’ capacity to significantly lower GANs’ computational demands but also pave the way for deploying high-quality GAN models in settings with limited resources. Our code will be released soon.
@inproceedings{yeo2024nickel, title = {Nickel and Diming Your GAN: A Dual-Method Approach to Enhancing GAN Efficiency via Knowledge Distillation}, author = {Yeo, Sangyeop and Jang, Yoojin and Yoo, Jaejun}, booktitle = {European Conference on Computer Vision (ECCV)}, year = {2024}, } - ICLR
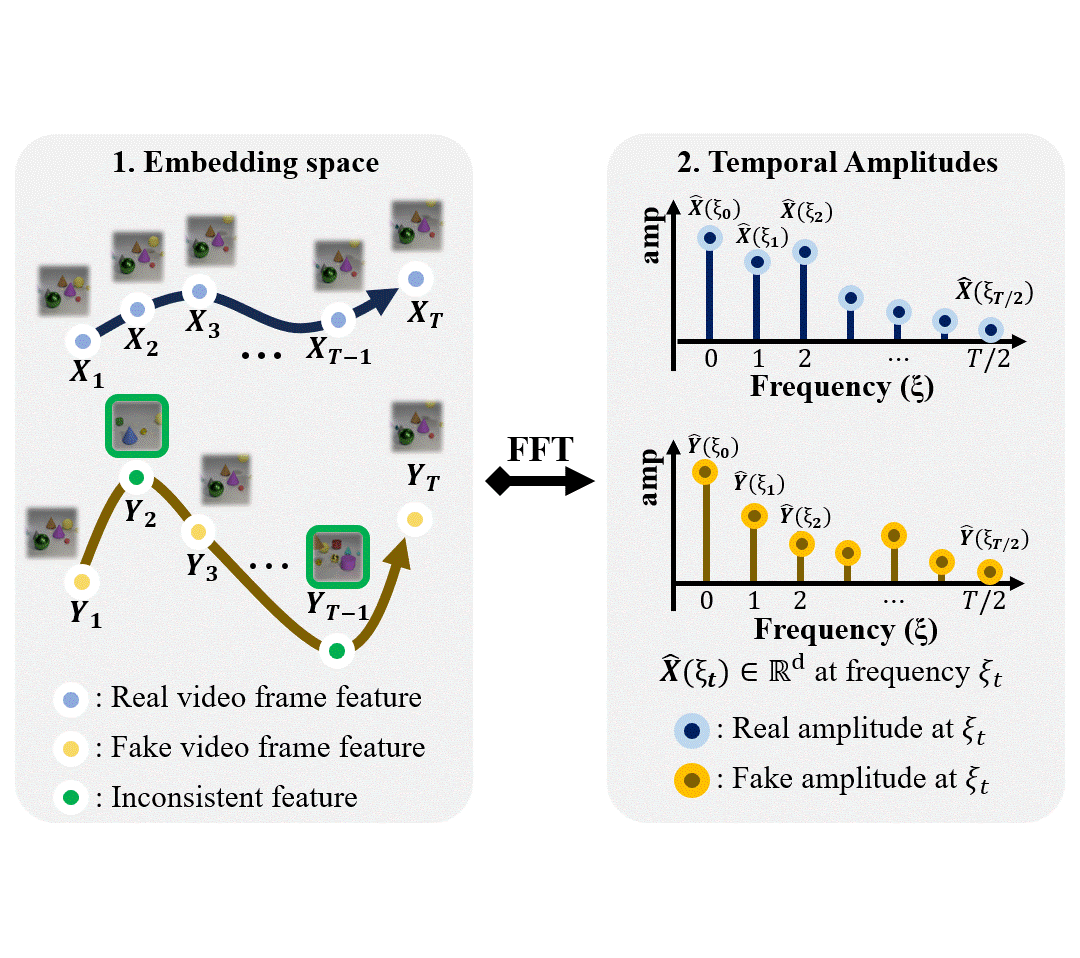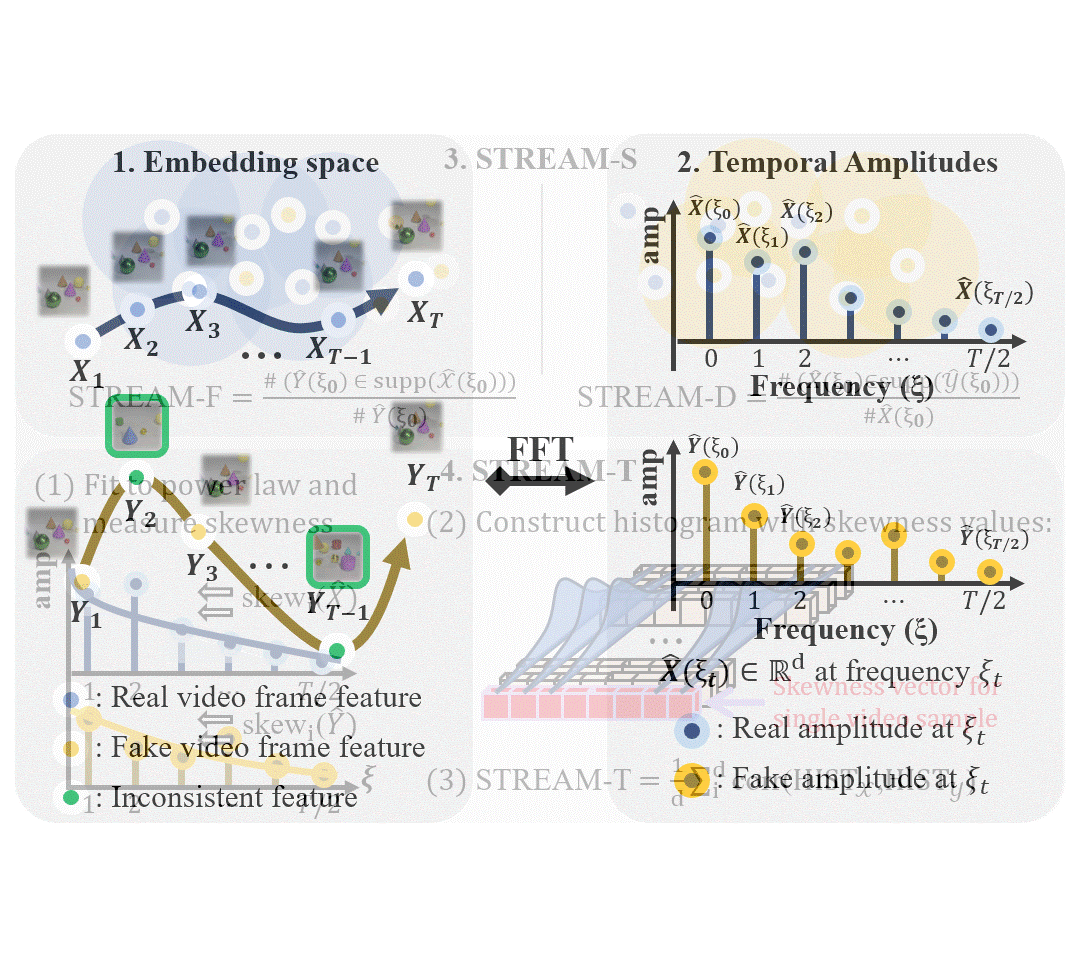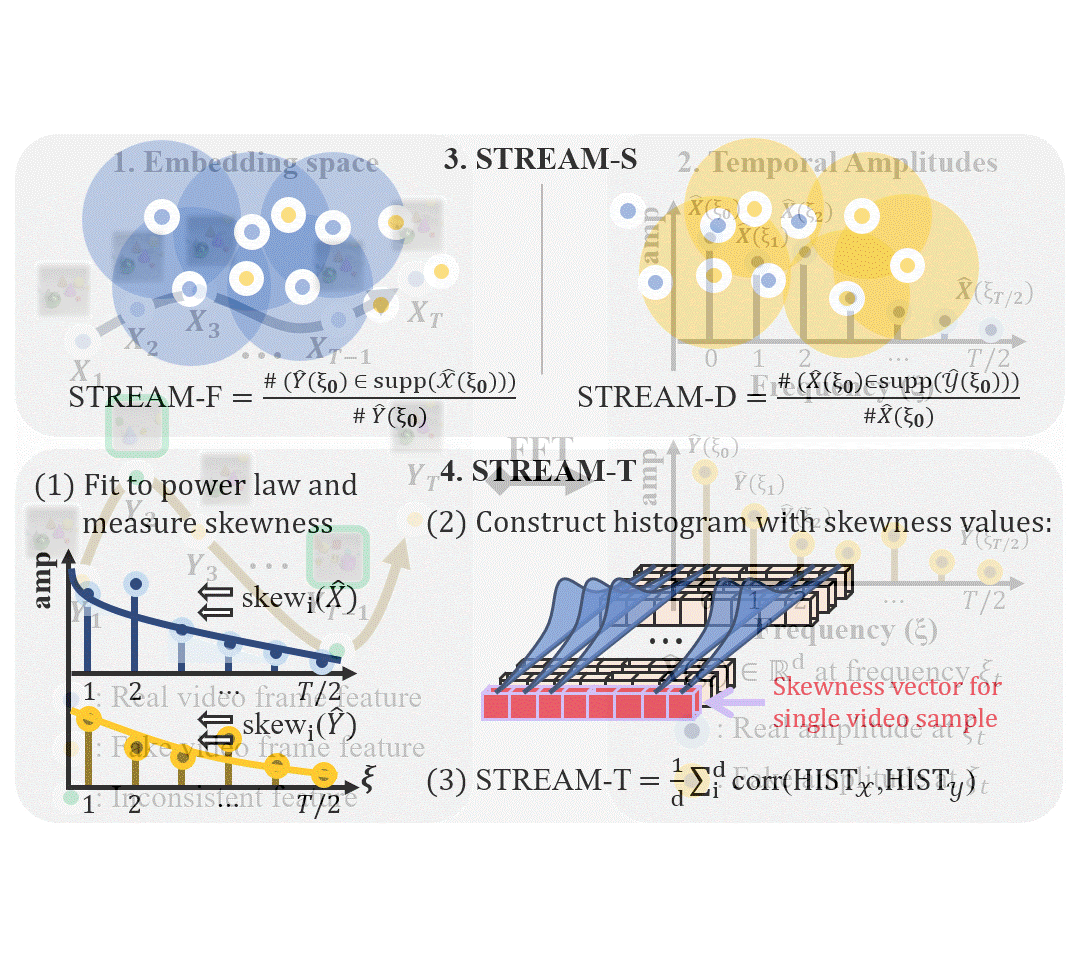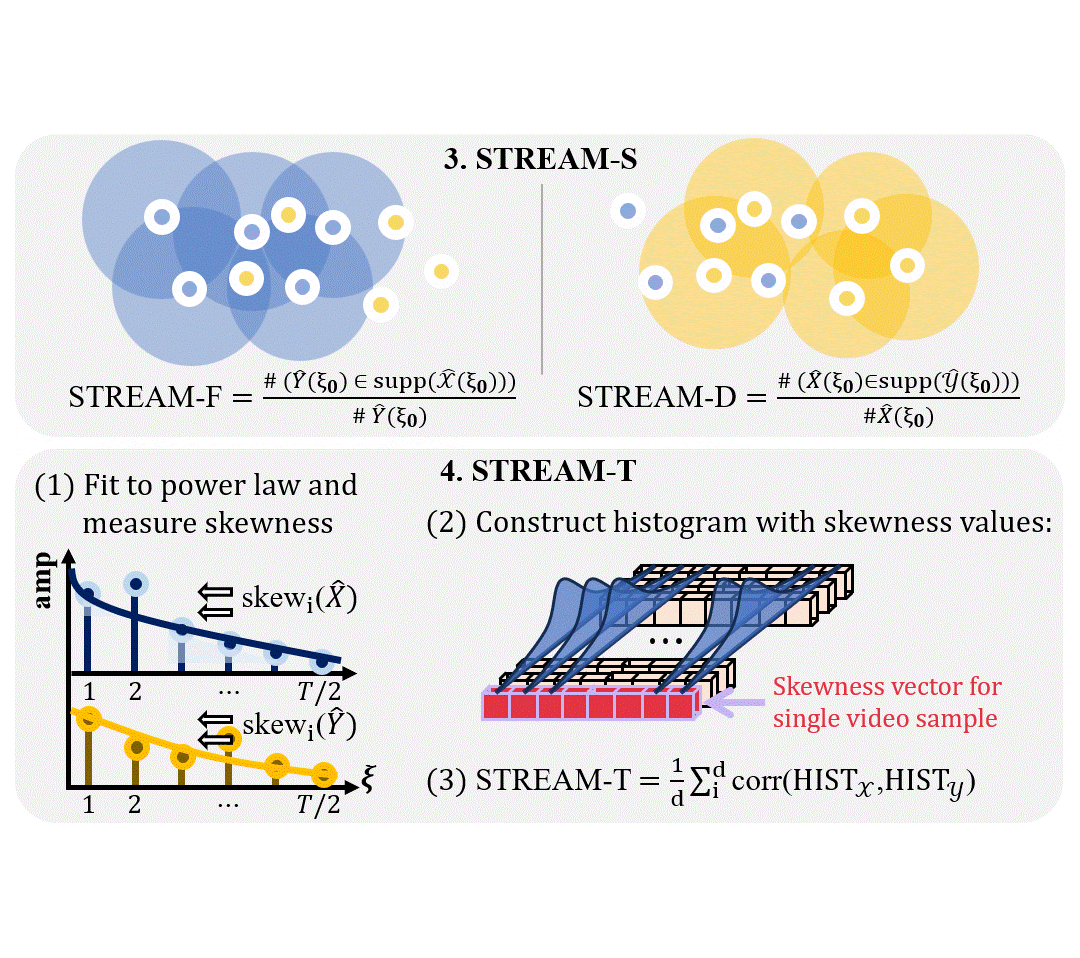
 STREAM: Spatio-TempoRal Evaluation and Analysis Metric for Video Generative ModelsPum Jun Kim, SeoJun Kim, and Jaejun YooIn International Conference on Learning Representations (ICLR), 2024
STREAM: Spatio-TempoRal Evaluation and Analysis Metric for Video Generative ModelsPum Jun Kim, SeoJun Kim, and Jaejun YooIn International Conference on Learning Representations (ICLR), 2024Image generative models have made significant progress in generating realistic and diverse images, supported by comprehensive guidance from various evaluation metrics. However, current video generative models struggle to generate even short video clips, with limited tools that provide insights for improvements. Current video evaluation metrics are simple adaptations of image metrics by switching the embeddings with video embedding networks, which may underestimate the unique characteristics of video. Our analysis reveals that the widely used Frechet Video Distance (FVD) has a stronger emphasis on the spatial aspect than the temporal naturalness of video and is inherently constrained by the input size of the embedding networks used, limiting it to 16 frames. Additionally, it demonstrates considerable instability and diverges from human evaluations. To address the limitations, we propose STREAM, a new video evaluation metric uniquely designed to independently evaluate spatial and temporal aspects. This feature allows comprehensive analysis and evaluation of video generative models from various perspectives, unconstrained by video length. We provide analytical and experimental evidence demonstrating that STREAM provides an effective evaluation tool for both visual and temporal quality of videos, offering insights into area of improvement for video generative models. To the best of our knowledge, STREAM is the first evaluation metric that can separately assess the temporal and spatial aspects of videos. Our code is available at https://github.com/pro2nit/STREAM.
@inproceedings{kim2024stream, title = {STREAM: Spatio-TempoRal Evaluation and Analysis Metric for Video Generative Models}, author = {Kim, Pum Jun and Kim, SeoJun and Yoo, Jaejun}, booktitle = {International Conference on Learning Representations (ICLR)}, year = {2024}, }
2023
- NeurIPS
 TopP&R: Robust Support Estimation Approach for Evaluating Fidelity and Diversity in Generative ModelsPum Jun Kim, Yoojin Jang, Jisu Kim, and 1 more authorIn Neural Information Processing Systems (NeurIPS), 2023
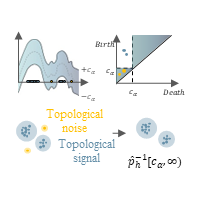
TopP&R: Robust Support Estimation Approach for Evaluating Fidelity and Diversity in Generative ModelsPum Jun Kim, Yoojin Jang, Jisu Kim, and 1 more authorIn Neural Information Processing Systems (NeurIPS), 2023We propose a robust and reliable evaluation metric for generative models by introducing topological and statistical treatments for rigorous support estimation. Existing metrics, such as Inception Score (IS), Frechet Inception Distance (FID), and the variants of Precision and Recall (P&R), heavily rely on supports that are estimated from sample features. However, the reliability of their estimation has not been seriously discussed (and overlooked) even though the quality of the evaluation entirely depends on it. In this paper, we propose Topological Precision and Recall (TopP&R, pronounced ’topper’), which provides a systematic approach to estimating supports, retaining only topologically and statistically important features with a certain level of confidence. This not only makes TopP&R strong for noisy features, but also provides statistical consistency. Our theoretical and experimental results show that TopP&R is robust to outliers and non-independent and identically distributed (Non-IID) perturbations, while accurately capturing the true trend of change in samples. To the best of our knowledge, this is the first evaluation metric focused on the robust estimation of the support and provides its statistical consistency under noise.
@inproceedings{kim2023toppr, title = {{TopP\&R}: Robust Support Estimation Approach for Evaluating Fidelity and Diversity in Generative Models}, author = {Kim, Pum Jun and Jang, Yoojin and Kim, Jisu and Yoo, Jaejun}, booktitle = {Neural Information Processing Systems (NeurIPS)}, year = {2023}, } - AAAI
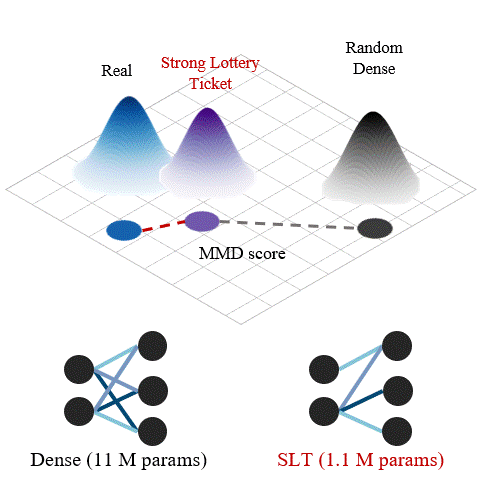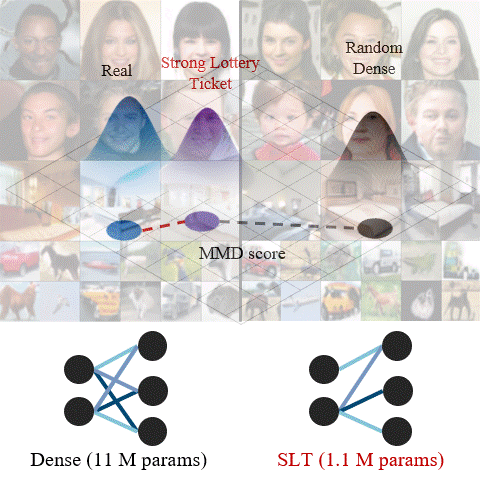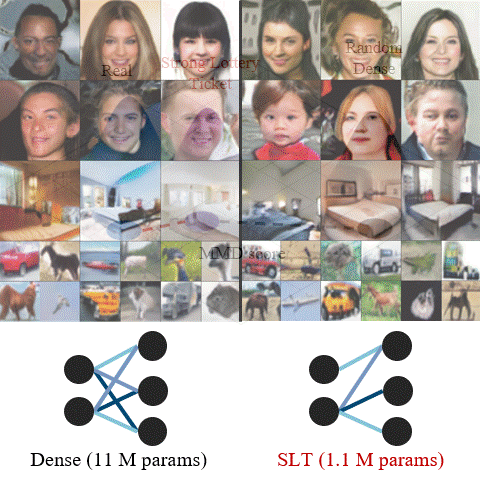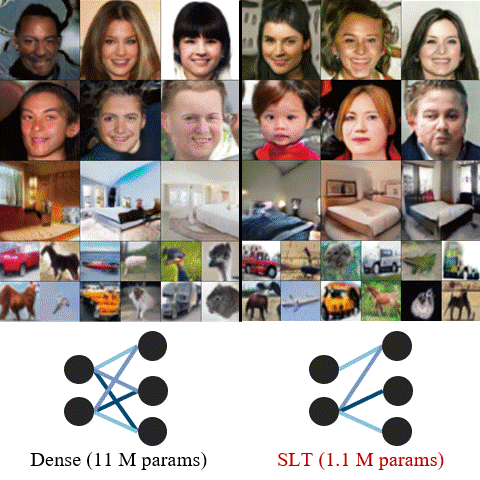
 Can We Find Strong Lottery Tickets in Generative Models?Sangyeop Yeo, Yoojin Jang, Jy-yong Sohn, and 2 more authorsIn AAAI Conference on Artificial Intelligence (AAAI), 2023
Can We Find Strong Lottery Tickets in Generative Models?Sangyeop Yeo, Yoojin Jang, Jy-yong Sohn, and 2 more authorsIn AAAI Conference on Artificial Intelligence (AAAI), 2023@inproceedings{yeo2023lottery, title = {Can We Find Strong Lottery Tickets in Generative Models?}, author = {Yeo, Sangyeop and Jang, Yoojin and Sohn, Jy-yong and Han, Dongyoon and Yoo, Jaejun}, booktitle = {AAAI Conference on Artificial Intelligence (AAAI)}, year = {2023}, }
2021
- ICCV
 Rethinking the Truly Unsupervised Image-to-Image TranslationKyungjune Baek, Yunjey Choi, Youngjung Uh, and 2 more authorsIn International Conference on Computer Vision (ICCV), 2021
Rethinking the Truly Unsupervised Image-to-Image TranslationKyungjune Baek, Yunjey Choi, Youngjung Uh, and 2 more authorsIn International Conference on Computer Vision (ICCV), 2021Every recent image-to-image translation model inherently requires either image-level (i.e. input-output pairs) or set-level (i.e. domain labels) supervision. However, even set-level supervision can be a severe bottleneck for data collection in practice. In this paper, we tackle image-to-image translation in a fully unsupervised setting, i.e., neither paired images nor domain labels. To this end, we propose a truly unsupervised image-to-image translation model (TUNIT) that simultaneously learns to separate image domains and translates input images into the estimated domains. Experimental results show that our model achieves comparable or even better performance than the set-level supervised model trained with full labels, generalizes well on various datasets, and is robust against the choice of hyperparameters (e.g. the preset number of pseudo domains). Furthermore, TUNIT can be easily extended to semi-supervised learning with a few labeled data.
@inproceedings{baek2021tunit, title = {Rethinking the Truly Unsupervised Image-to-Image Translation}, author = {Baek, Kyungjune and Choi, Yunjey and Uh, Youngjung and Yoo, Jaejun and Shim, Hyunjung}, booktitle = {International Conference on Computer Vision (ICCV)}, year = {2021}, } - IEEE TMI
 Time-Dependent Deep Image Prior for Dynamic MRIJaejun Yoo, Kyong Hwan Jin, Harshit Gupta, and 3 more authorsIEEE Transactions on Medical Imaging, 2021
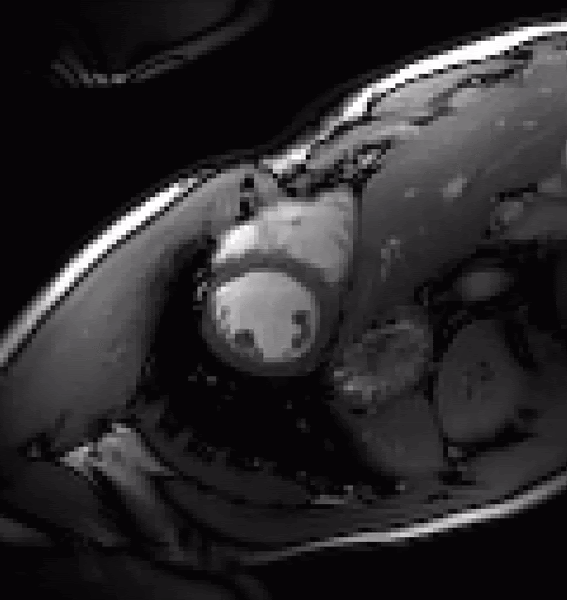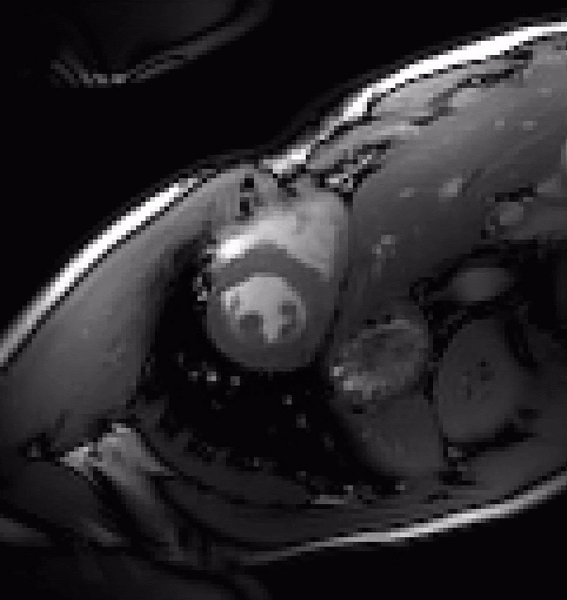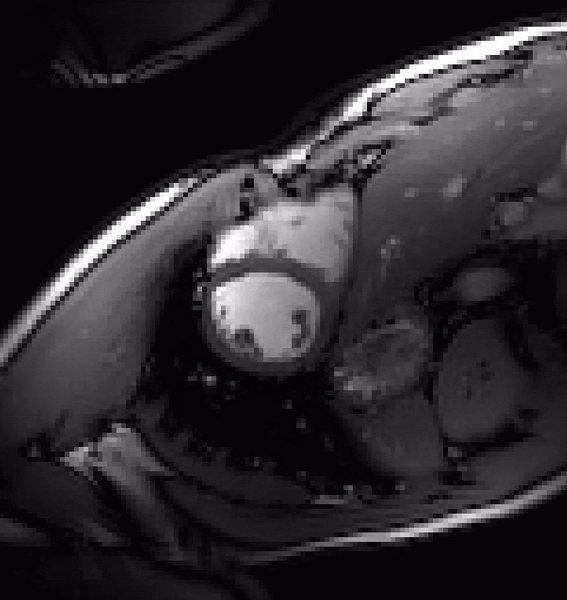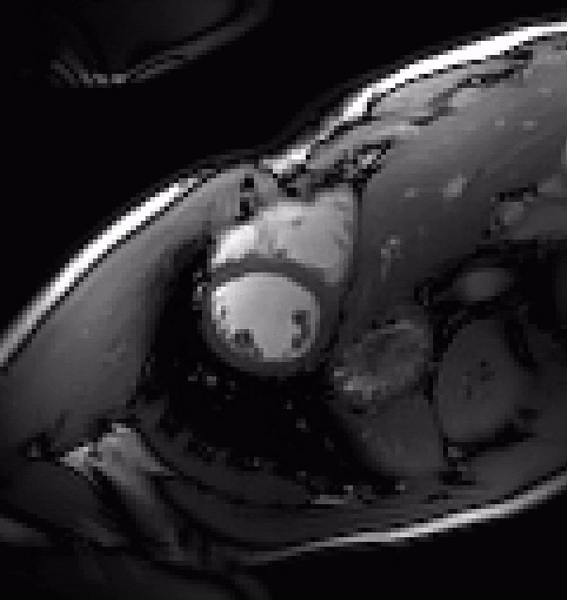
Time-Dependent Deep Image Prior for Dynamic MRIJaejun Yoo, Kyong Hwan Jin, Harshit Gupta, and 3 more authorsIEEE Transactions on Medical Imaging, 2021We propose a novel unsupervised deep-learning-based algorithm for dynamic magnetic resonance imaging (MRI) reconstruction. Dynamic MRI requires rapid data acquisition for the study of moving organs such as the heart. We introduce a generalized version of the deep-image-prior approach, which optimizes the weights of a reconstruction network to fit a sequence of sparsely acquired dynamic MRI measurements. Our method needs neither prior training nor additional data. In particular, for cardiac images, it does not require the marking of heartbeats or the reordering of spokes. The key ingredients of our method are threefold: 1) a fixed low-dimensional manifold that encodes the temporal variations of images; 2) a network that maps the manifold into a more expressive latent space; and 3) a convolutional neural network that generates a dynamic series of MRI images from the latent variables and that favors their consistency with the measurements in {k} -space. Our method outperforms the state-of-the-art methods quantitatively and qualitatively in both retrospective and real fetal cardiac datasets. To the best of our knowledge, this is the first unsupervised deep-learning-based method that can reconstruct the continuous variation of dynamic MRI sequences with high spatial resolution.
@article{yoo2021tddip, title = {Time-Dependent Deep Image Prior for Dynamic {MRI}}, author = {Yoo, Jaejun and Jin, Kyong Hwan and Gupta, Harshit and Yerly, Jerome and Stuber, Matthias and Unser, Michael}, journal = {IEEE Transactions on Medical Imaging}, year = {2021}, }
2020
- ICML
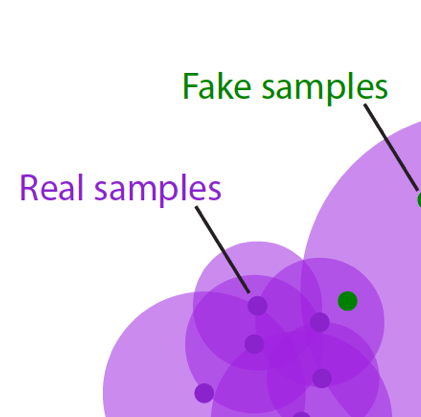
 Reliable Fidelity and Diversity Metrics for Generative ModelsMuhammad Ferjad Naeem*, Seong Joon Oh*, Youngjung Uh, and 2 more authorsIn International Conference on Machine Learning (ICML), 2020
Reliable Fidelity and Diversity Metrics for Generative ModelsMuhammad Ferjad Naeem*, Seong Joon Oh*, Youngjung Uh, and 2 more authorsIn International Conference on Machine Learning (ICML), 2020Devising indicative evaluation metrics for the image generation task remains an open problem. The most widely used metric for measuring the similarity between real and generated images has been the Frechet Inception Distance (FID) score. Because it does not differentiate the fidelity and diversity aspects of the generated images, recent papers have introduced variants of precision and recall metrics to diagnose those properties separately. In this paper, we show that even the latest version of the precision and recall metrics are not reliable yet. For example, they fail to detect the match between two identical distributions, they are not robust against outliers, and the evaluation hyperparameters are selected arbitrarily. We propose density and coverage metrics that solve the above issues. We analytically and experimentally show that density and coverage provide more interpretable and reliable signals for practitioners than the existing metrics. Code: this https URL.
@inproceedings{naeem2020reliable, title = {Reliable Fidelity and Diversity Metrics for Generative Models}, author = {Naeem, Muhammad Ferjad and Oh, Seong Joon and Uh, Youngjung and Choi, Yunjey and Yoo, Jaejun}, booktitle = {International Conference on Machine Learning (ICML)}, year = {2020}, } - CVPR
 StarGAN v2: Diverse Image Synthesis for Multiple DomainsYunjey Choi*, Youngjung Uh*, Jaejun Yoo*, and 1 more authorIn IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2020
StarGAN v2: Diverse Image Synthesis for Multiple DomainsYunjey Choi*, Youngjung Uh*, Jaejun Yoo*, and 1 more authorIn IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2020A good image-to-image translation model should learn a mapping between different visual domains while satisfying the following properties: 1) diversity of generated images and 2) scalability over multiple domains. Existing methods address either of the issues, having limited diversity or multiple models for all domains. We propose StarGAN v2, a single framework that tackles both and shows significantly improved results over the baselines. Experiments on CelebA-HQ and a new animal faces dataset (AFHQ) validate our superiority in terms of visual quality, diversity, and scalability. To better assess image-to-image translation models, we release AFHQ, high-quality animal faces with large inter- and intra-domain differences. The code, pretrained models, and dataset are available at https://github.com/clovaai/stargan-v2.
@inproceedings{choi2020stargan2, title = {StarGAN v2: Diverse Image Synthesis for Multiple Domains}, author = {Choi, Yunjey and Uh, Youngjung and Yoo, Jaejun and Ha, Jung-Woo}, booktitle = {IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)}, year = {2020}, } - CVPR
 Rethinking Data Augmentation for Image Super-resolution: A Comprehensive Analysis and a New StrategyJaejun Yoo*, Namhyuk Ahn*, and Kyung Ah SohnIn IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2020
Rethinking Data Augmentation for Image Super-resolution: A Comprehensive Analysis and a New StrategyJaejun Yoo*, Namhyuk Ahn*, and Kyung Ah SohnIn IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2020Data augmentation is an effective way to improve the performance of deep networks. Unfortunately, current methods are mostly developed for high-level vision tasks (e.g., classification) and few are studied for low-level vision tasks (e.g., image restoration). In this paper, we provide a comprehensive analysis of the existing augmentation methods applied to the super-resolution task. We find that the methods discarding or manipulating the pixels or features too much hamper the image restoration, where the spatial relationship is very important. Based on our analyses, we propose CutBlur that cuts a low-resolution patch and pastes it to the corresponding high-resolution image region and vice versa. The key intuition of CutBlur is to enable a model to learn not only "how" but also "where" to super-resolve an image. By doing so, the model can understand "how much", instead of blindly learning to apply super-resolution to every given pixel. Our method consistently and significantly improves the performance across various scenarios, especially when the model size is big and the data is collected under real-world environments. We also show that our method improves other low-level vision tasks, such as denoising and compression artifact removal.
@inproceedings{yoo2020cutblur, title = {Rethinking Data Augmentation for Image Super-resolution: A Comprehensive Analysis and a New Strategy}, author = {Yoo, Jaejun and Ahn, Namhyuk and Sohn, Kyung Ah}, booktitle = {IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)}, year = {2020}, }
2019
- ICCV
 Photorealistic Style Transfer via Wavelet TransformsJaejun Yoo*, Youngjung Uh*, Sanghyuk Chun*, and 2 more authorsIn International Conference on Computer Vision (ICCV), 2019
Photorealistic Style Transfer via Wavelet TransformsJaejun Yoo*, Youngjung Uh*, Sanghyuk Chun*, and 2 more authorsIn International Conference on Computer Vision (ICCV), 2019Recent style transfer models have provided promising artistic results. However, given a photograph as a reference style, existing methods are limited by spatial distortions or unrealistic artifacts, which should not happen in real photographs. We introduce a theoretically sound correction to the network architecture that remarkably enhances photorealism and faithfully transfers the style. The key ingredient of our method is wavelet transforms that naturally fits in deep networks. We propose a wavelet corrected transfer based on whitening and coloring transforms (WCT2) that allows features to preserve their structural information and statistical properties of VGG feature space during stylization. This is the first and the only end-to-end model that can stylize a 1024x1024 resolution image in 4.7 seconds, giving a pleasing and photorealistic quality without any post-processing. Last but not least, our model provides a stable video stylization without temporal constraints. Our code, generated images, pre-trained models and supplementary documents are all available at https://github.com/ClovaAI/WCT2.
@inproceedings{yoo2019wct2, title = {Photorealistic Style Transfer via Wavelet Transforms}, author = {Yoo, Jaejun and Uh, Youngjung and Chun, Sanghyuk and Kang, Byeongkyu and Ha, Jung-Woo}, booktitle = {International Conference on Computer Vision (ICCV)}, year = {2019}, }